Όταν η Google δεν «γνωρίζει» μία σελίδα δεν την εμφανίζει πουθενά.
Η Google δεν καταγράφει όλες τις σελίδες για διάφορους λόγους. Το ποσοστό των σελίδων ενός website που δεν καταγράφονται εξαρτάται από τον τύπο, τον τρόπο σχεδιασμού και το μέγεθος του και μπορεί να φτάσει ακόμη και πάνω από το 50%.
Εάν οι σελίδες που δεν έχουν καταγραφεί δεν είναι σημαντικές όπως η πολιτική απορρήτου, δεν υπάρχει πρόβλημα. Τι γίνεται όμως όταν αυτό συμβαίνει με σελίδες όπως π.χ. των προϊόντων ή των υπηρεσιών;
Θα γράψω για αυτά τα σύνθετα ζητήματα ξεκινώντας με τον τρόπο με τον οποίο η Google βρίσκει τις σελίδες, τις αναλύει και ενδεχομένως τις καταγράφει.
Google Crawler
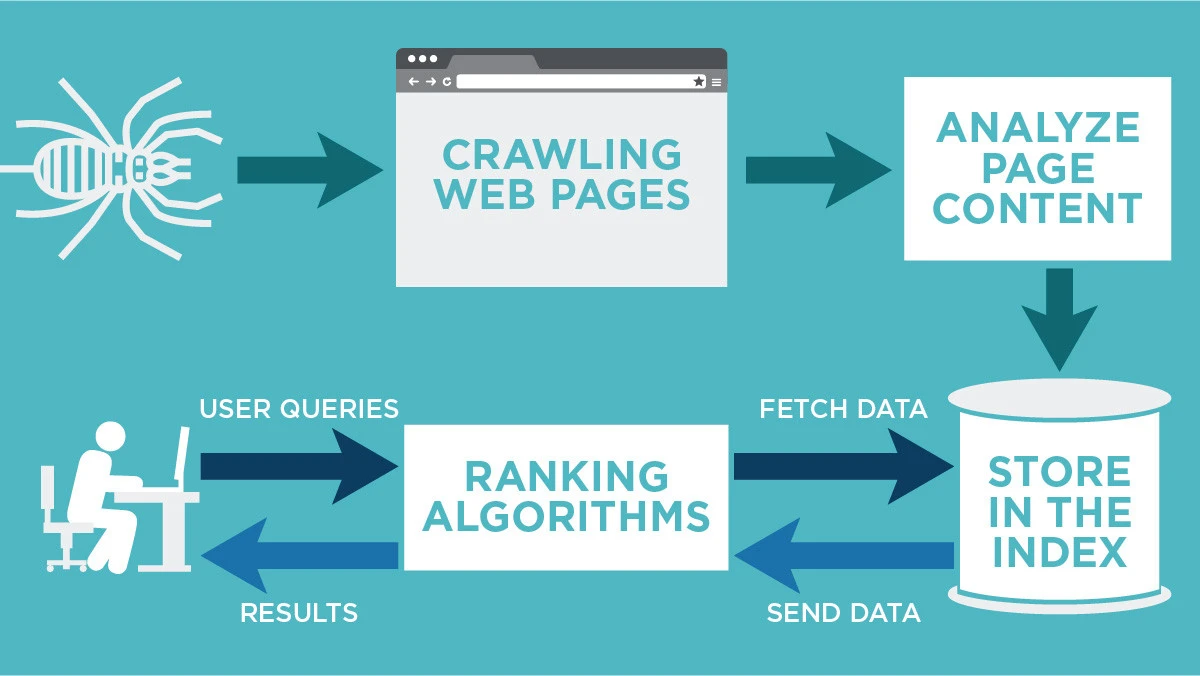
H Google για τη διαδικασία της σάρωσης του Internet, του εντοπισμού και της καταγραφής των σελίδων, χρησιμοποιεί ένα είδος λογισμικού, τον Google crawler (ή Googlebot, spider κτλ).
Discovery
Εφόσον δεν υπάρχει ένας κεντρικός κατάλογος στον οποίο να καταγράφονται αυτόματα όλες οι σελίδες, η Google θα πρέπει με κάποιο τρόπο να τις ανακαλύψει. Αυτό γίνεται με τον Google crawler ο οποίος περιπλανάται στο Internet πηγαίνοντας από τη μία σελίδα στην άλλη μέσω των links που βρίσκει, ψάχνοντας για νέο ή ενημερωμένο περιεχόμενο και σελίδες που δεν υπάρχουν ήδη στη βάση της Google. Ο crawler μπορεί να λάβει πληροφορίες για κάτι καινούργιο και από τα XML sitemaps.
Crawling
Μόλις η Google ανακαλύψει μια URL πρεπει να την επισκεφθεί (crawl) για να μάθει τι υπάρχει σε αυτήν. Όμως η Google δεν κάνει crawl όλες τις σελίδες που βρίσκει. Χρησιμοποιεί αλγόριθμους για να καθορίσει ποιες από τις σελίδες και με ποια προτεραιότητα θα κάνει crawl, ανάλογα με το πόσο “σημαντικές” τις θεωρεί.
Rendering
Η Google επισκέπτεται την σελίδα και την αναπαραγάγει (render) με μία διαδικασία παρόμοια με τον τρόπο που βλέπουμε τις σελίδες στους browsers μας και ειδικότερα τον Chrome. Αυτό γίνεται για να καταλάβει πως είναι σχεδιασμένη η σελίδα, το περιεχόμενο και την λειτουργικότητα της, με έμφαση στον τρόπο που εμφανίζεται και λειτουργεί στα κινητά τηλέφωνα.
Indexing
Στο τέλος η Google αναλύει το περιεχόμενο, τα κείμενα, τις φωτογραφίες, και αξιολογεί την ποιότητα τους για να αποφασίσει εάν η σελίδα είναι κατάλληλη για να εμφανίζεται στα αποτελέσματα των αναζητήσεων. Εάν όλα πάνε καλά τότε η σελίδα αποθηκεύεται στο Google Ιndex, τη βάση δεδομένων από την οποία η Google αντλεί τα αποτελέσματα των αναζητήσεων.